如何使用Terraform在AWS上扩展Buddy自托管

本文,我们将展示如何在Buddy创建一个流水线并在流水线上通过使用Terraform,自动扩展在AWS基础设施中添加或删除Buddy自托管额外的工作器。
由于每家公司使用的开发运维/自动化运维目的不同,该指南仅作为配置您自己扩展过程的一个参考。
工作器变量
本指南基于Buddy工作器变量进行开展;一种作为Buddy工作器使用行为的新型环境变量。变量可在每次流水线运行开始前生成,可用于流水线中的所有操作。您可以使用所创建的变量来计算需要多少工作器来为您的工作负载提供服务,将当前负载发送到CloudWatch、Datadog、New Relic或者在Telegram、Slack频道等上通知您的团队。
在此示例中,我们使用脚本中的变量来更新Terraform配置并启动或关闭AWS中的EC2实例。
| 名称 | 值 |
|---|---|
| BUDDY_WORKERS 包含所有已安装工作器的JSON信息 | {"workers":[{"name":"Primary","address":"build-server","status":"RUNNING","load":0.56,"free_slots":4,"tag":"NOT_TAGGED","locked":false}],"tags":[{"name":"NOT_TAGGED","avg_load":0.56,"free_slots":4,"workers_quantity":1}]} |
| BUDDYWORKERS_ADDRESS${TAG} 用 ${TAG}标记的工作器IP地址列表 | 192.168.4.11 |
| BUDDY_WORKERS_ADDRESS_NOT_TAGGED 未标记工作器的IP地址列表 | build-server |
| BUDDYWORKERS_AVG_LOAD${TAG} 所有标有 ${TAG}工作器一分钟的平均负载 | 0.69 |
| BUDDY_WORKERS_AVG_LOAD_NOT_TAGGED 所有未标记工作器一分钟的平均负载 | 2.03 |
| BUDDY_WORKERS_CONCURRENT_SLOTS 所有工作器的流水线槽总数 | 4 |
| BUDDYWORKERS_COUNT${TAG} 标记有 ${TAG}的工作器数量 | 1 |
| BUDDY_WORKERS_COUNT_NOT_TAGGED 未标记的工作器数量 | 1 |
| BUDDYWORKERS_FREE_SLOTS${TAG} 标记有 ${TAG}的工作器空闲流水线槽数 | 4 |
| BUDDY_WORKERS_FREE_SLOTS_NOT_TAGGED 所有未标记的工作器空闲流水线槽数 | 4 |
第一部分:项目配置
1. 分叉存储仓
首先,分叉此存储仓到您自己的GitHub帐户上:https://github.com/buddy-red/workers-scale
此存储仓包含示例所需的两个作用:
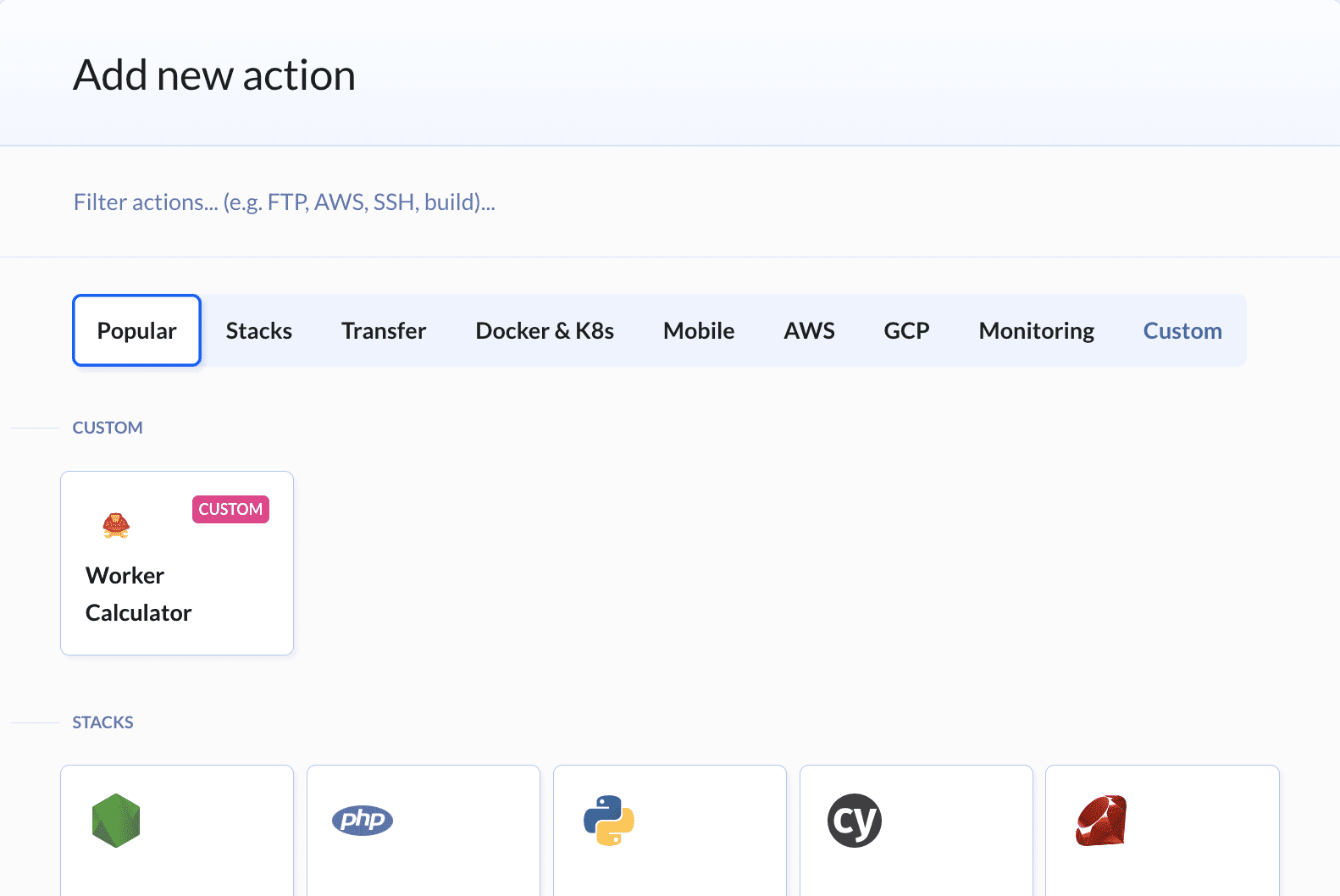
工作器计算器(action.yml) - 这是一个计算本地网络负载的自定义操作。当负载超过限制时,操作的输出可作为通知中的变量发送。如若必要您还可以在脚本中使用它添加或删除工作器(见下文)。
扩展流水线(/example_pipeline) - 一个预配置流水线,使用Terraform根据计算器的输出启动或关闭EC2实例。该流水线包含示例数据,可以交换这些数据以使其与您的基础架构一起使用。
该目录/文件夹包含以下文件:
- buddy.yml - 定义流水线的操作执行
- install.tmpl.sh - 在新机器上安装Buddy的脚本模板
- main.tf与vars.tf - Terraform配置文件
- scale.sh - 更新Terraform配置的脚本
2. 同步项目
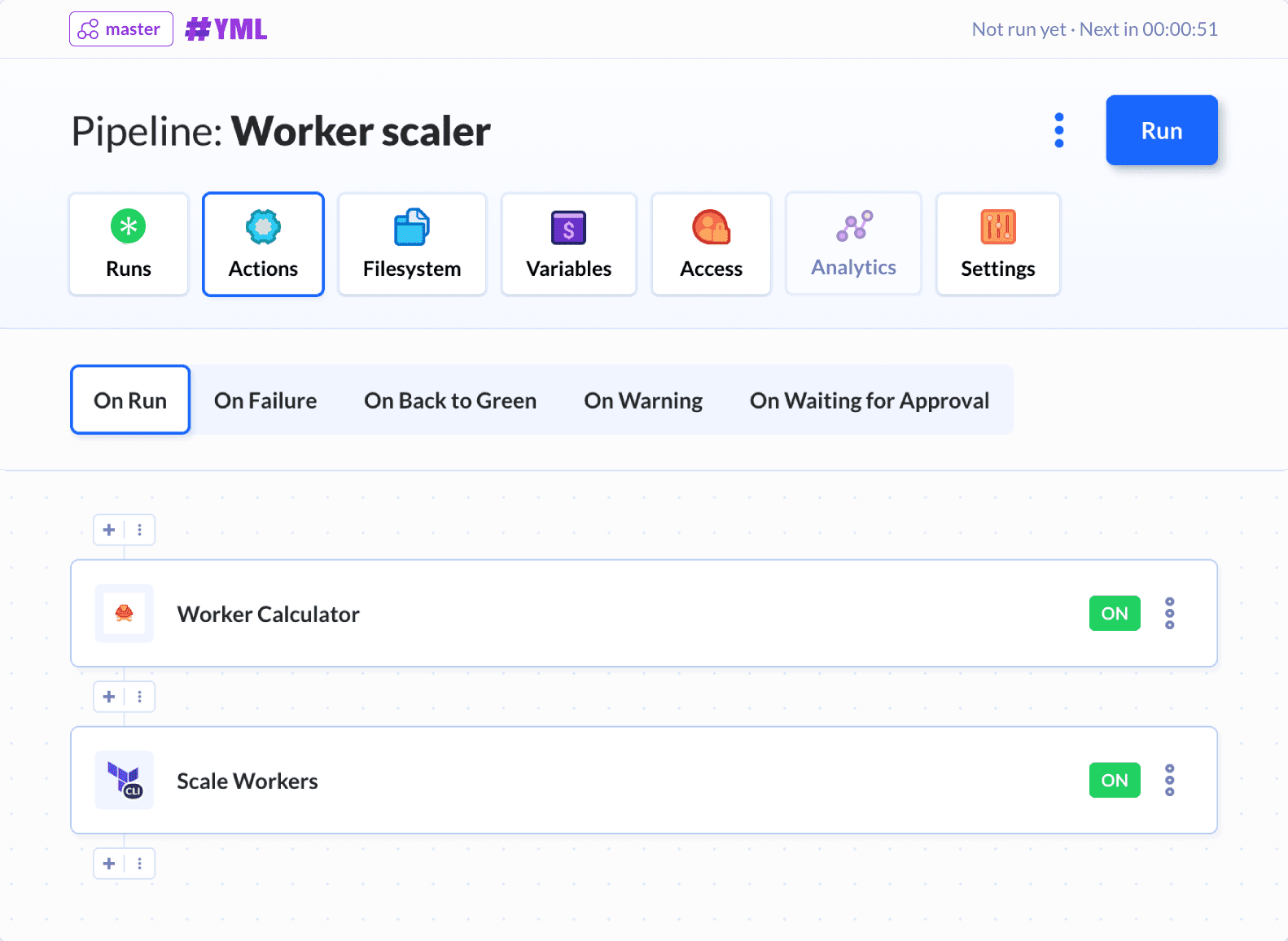
在Buddy中新建一个项目,选择您的Git提供商,然后添加分叉的存储仓。Buddy将根据buddy.yml定义自动创建流水线:
 |
|---|
 |
|---|
这些文件必须存储在根目录中,否则将不会检测到流水线配置。
若流水线仍然没有显示,请查看相关动态日志记录。您可能也得从Scale workers(扩展工作器)操作中清除Terraform的变量值。
此外,计算器将一直被添加到操作列表中:
 |
|---|
第二部分:流水线概览
流水线的配置存储在buddy.yml中。在指南的这一部分,我们将从上到下跟踪文件并展示Buddy如何解析输入数据以在应用程序中创建流水线。
1. 流水线设置
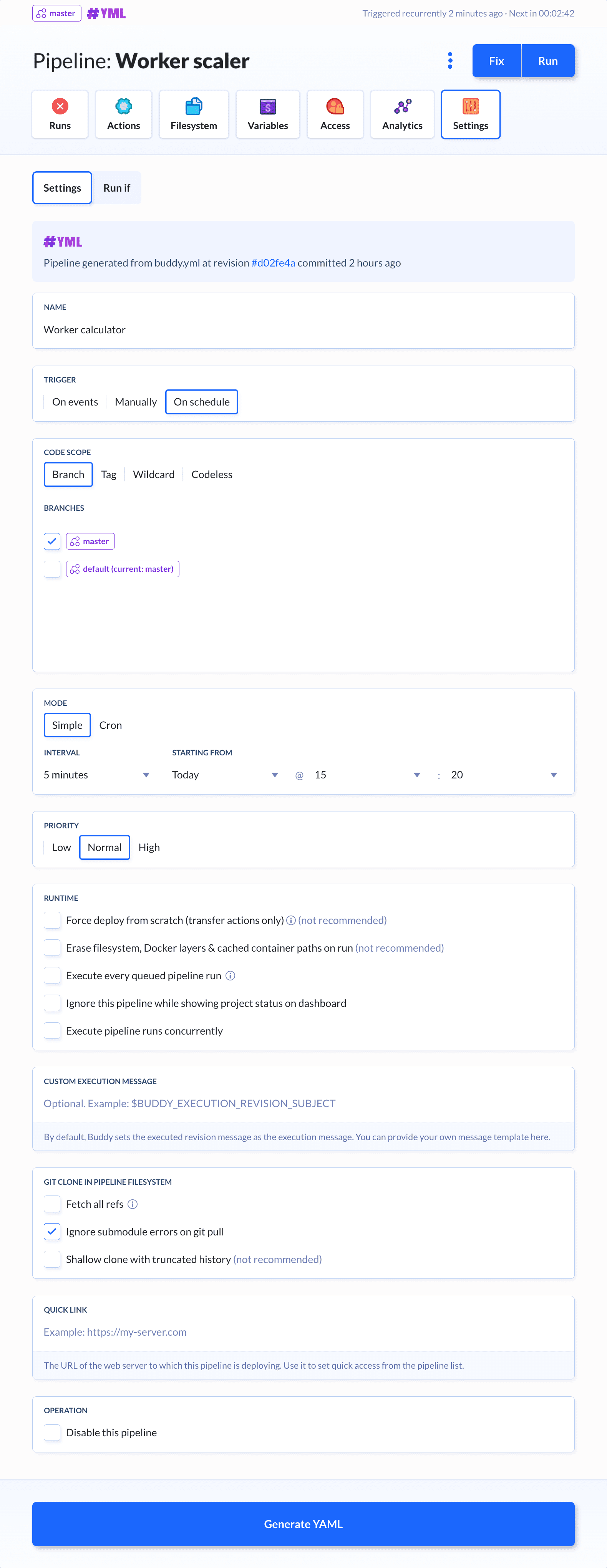
第一部分描述流水线作用:触发模式、分配的分支和运行之间的时间间隔。我们可以看到主分支每5分钟按定时运行一次:
- pipeline: Scale Workers
on: SCHEDULE
delay: 5
start_date: "2022-01-01T00:00:00Z"
tags:
- manage
refs:
- ":default"
确保相应地更新日期!对于设置为已过去的日期,流水线将不会启动运行。
在应用程序中,流水线运行时详细信息在“设置”选项卡中可用:
 |
|---|
您可直接在应用程序中更新流水线配置。之后,单击“生成YAML”并将其更新于buddy.yml文件中的代码。
2. 工作器计算器
继续往下来到actions操作部分,第一个便是Worker Calculator工作器计算器:
actions:
- action: Calculate Workers
type: CUSTOM
custom_type: Workers_Scale:latest
inputs:
WORKER_TAG: ""
WORKER_SLOTS: "2"
MAX_WORKERS: "2"
MIN_FREE_SLOTS: "1"
Input 输入
输入描述了工作器的配置,以及所需的空闲槽数。
- WORKER_TAG – 运行操作计算工作器的标签,如果您想扩展无标签的工作器,请留空。
- WORKER_SLOTS – 每个工作器的并发插槽数,即可以同时运行多少个流水线或操作。留空以获取您帐户所设置的值。
- MAX_WORKERS – 在您本地部署/自托管部署中启用的最大工作器数量
- MIN_FREE_SLOTS – 实例中所需的空闲槽数,用于计算是否为给定标签添加或删除工作器。
在此示例中:
- 标签字段为空,说明仅指向未标记的工作器
- 实例中的每个工作器都有2个并发槽
- 最多可同时运行2个工作器
- 每个工作器上应始终有1个插槽可用
Output 输出
输入数据被传递给生成三个变量的calc.sh:
WORKER_TAG– 运行操作的工作器标签WORKER_SLOTS– 每个工作器并发槽数WORKERS– 工作器优化出的数量
3. Terraform
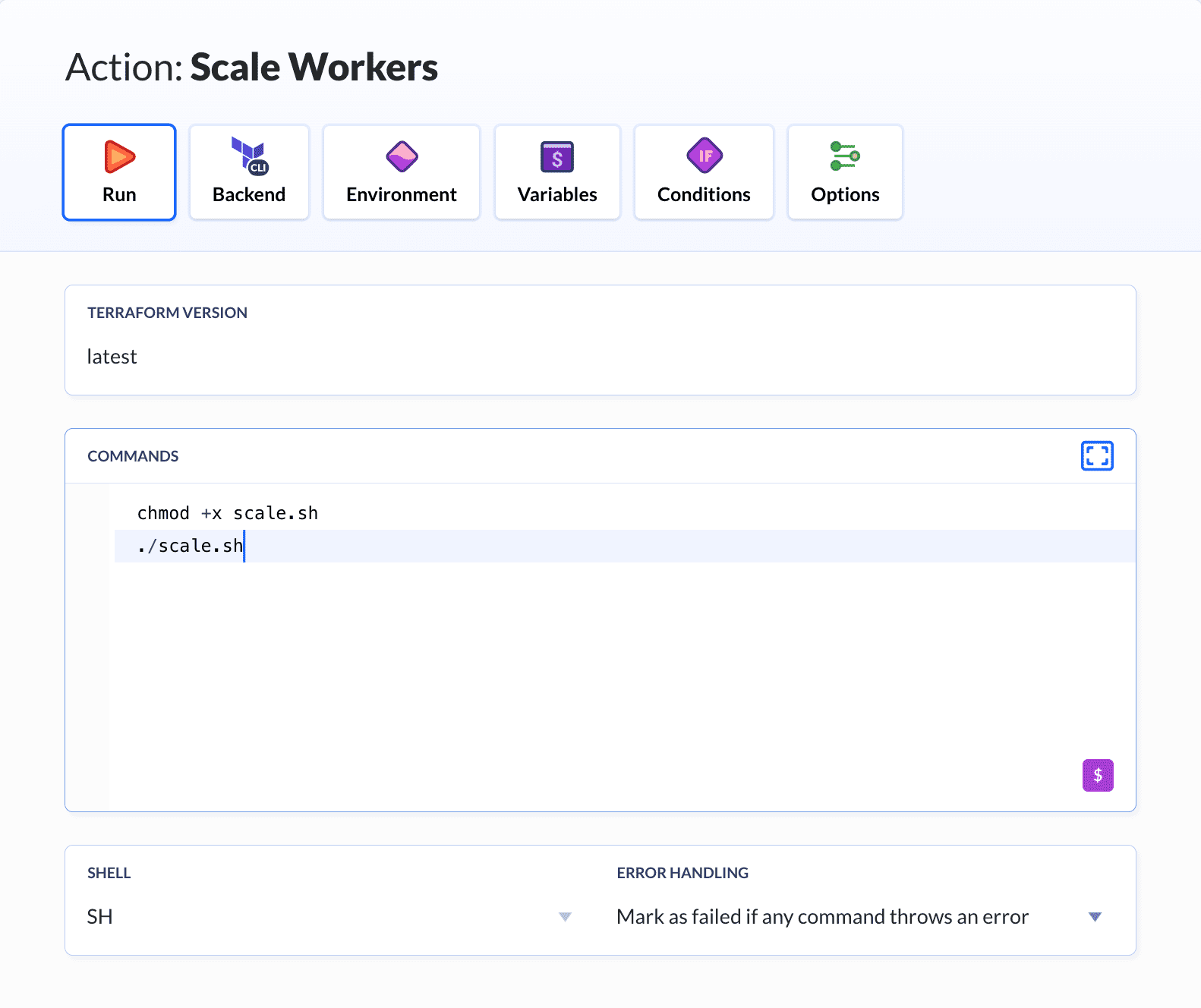
第二个操作是Terraform,它实质上将工作器添加到实例中。该操作运行scale.sh脚本,该脚本使用工作器计算器的输出更新Terraform的配置。
 |
|---|
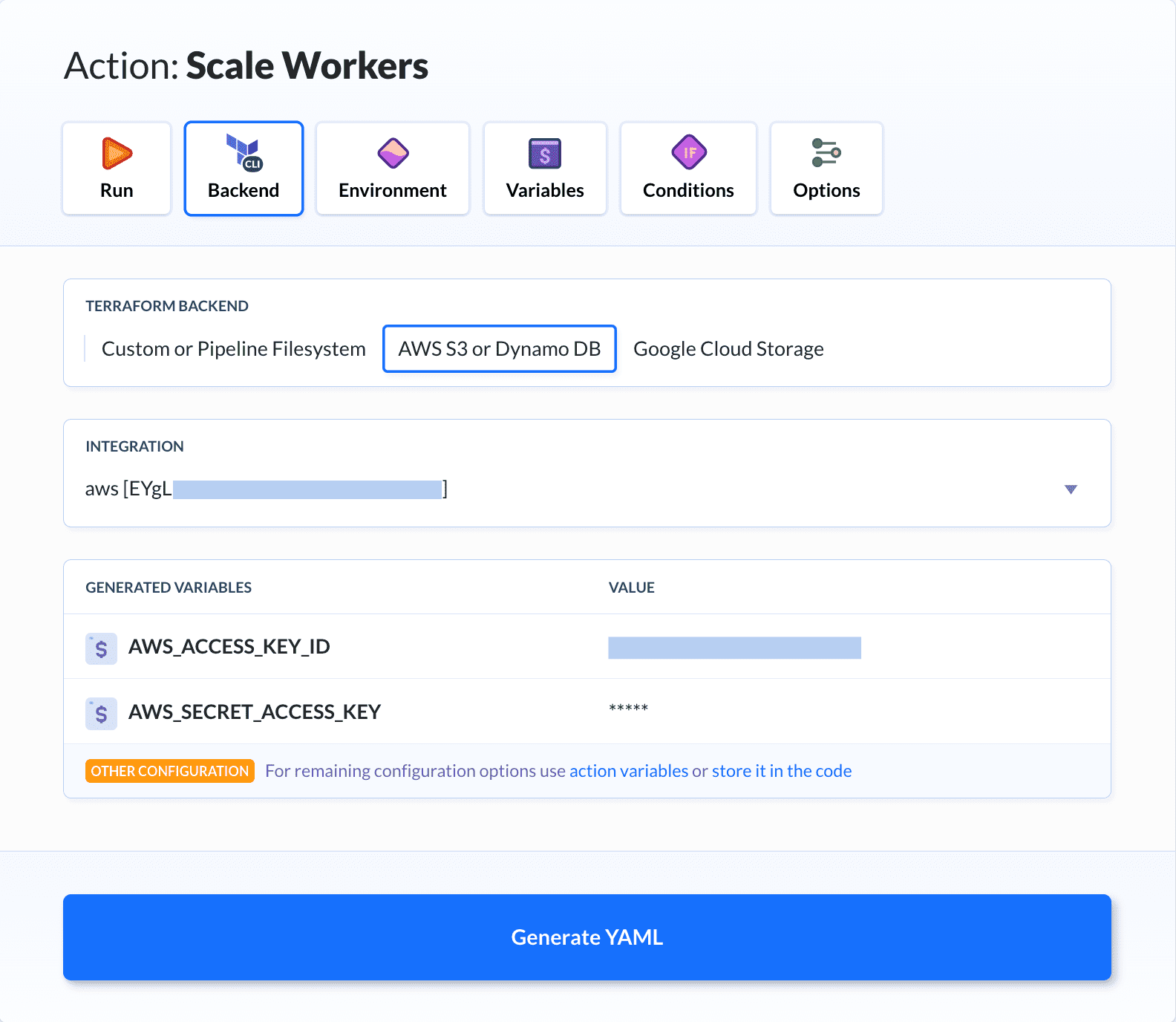
"后端"选项卡描述存储配置的AWS存储桶:
 |
|---|
- action: Scale Workers
type: TERRAFORM
version: latest
variables:
- key: AWS_REGION
value: "eu-central-1"
- key: AWS_AZ
value: "eu-central-1c"
- key: INSTANCE_PRIVATE_KEY
value: "[PRIVATE KEY TO CONNECT TO WORKER]"
- key: INSTANCE_PUBLIC_KEY
value: "[PUBLIC KEY TO CONNECT TO WORKER]"
- key: INSTANCE_TYPE
value: "t3.medium"
- key: INSTANCE_AMI_ID
value: "ami-06ce824c157700cd2"
- key: INSTANCE_VOLUME_SIZE
value: "50"
- key: INSTANCE_VOLUME_THROUGHPUT
value: "125"
- key: INSTANCE_VOLUME_IOPS
value: "3000"
- key: STANDALONE_HOST
value: "172.31.15.212"
- key: STANDALONE_TOKEN
value: "[ON-PREMISES WORKER TOKEN]"
- key: BACKEND_BUCKET
value: "[BUCKET ON S3 TO SAVE TERRAFORM STATE]"
- key: BACKEND_KEY
value: "workers.tfstate"
execute_commands:
- chmod +x scale.sh
- ./scale.sh
integration_hash: "[AWS INTEGRATION HASH]"
Terraform 变量
在本文第四部分,我们可以看到需要填写才能工作的变量:
| 名称 | 描述 |
|---|---|
| $AWS_REGION | 托管工作器的AWS区域 |
| $AWS_AZ | AWS的可用区域 |
| $INSTANCE_PRIVATE_KEY | 工作器上上使用的SSH私钥 |
| $INSTANCE_PUBLIC_KEY | 工作器上上使用的SSH公钥 |
| $INSTANCE_TYPE | 托管工作器的实例类型 |
| $INSTANCE_AMI_ID | 在实例上启动工作的的AMI ID(例如:Ubuntu in Ohio region) |
| $INSTANCE_VOLUME_SIZE | 实例中磁盘的大小(以GB为单位) |
| $INSTANCE_VOLUME_THROUGHPUT | 实例中磁盘的速度(以MB/秒为单位) |
| $INSTANCE_VOLUME_IOPS | 实例中磁盘设置的每秒输入操作数 |
| $STANDALONE_HOST | 实例中主工作器(主机)的IP地址 |
| $STANDALONE_TOKEN | 在实例中主工作器(主机)上生成的工作器令牌 |
| $BACKEND_BUCKET | AWS上的S3存储桶,其中Terraform保持其当前状态 |
| $BACKEND_KEY | S3存储桶中具有当前Terraform状态的文件名称 |
第三部分:AWS配置
此部分介绍在AWS EC2上安装Buddy、为Terraform配置创建存储桶以及生成SSH密钥。
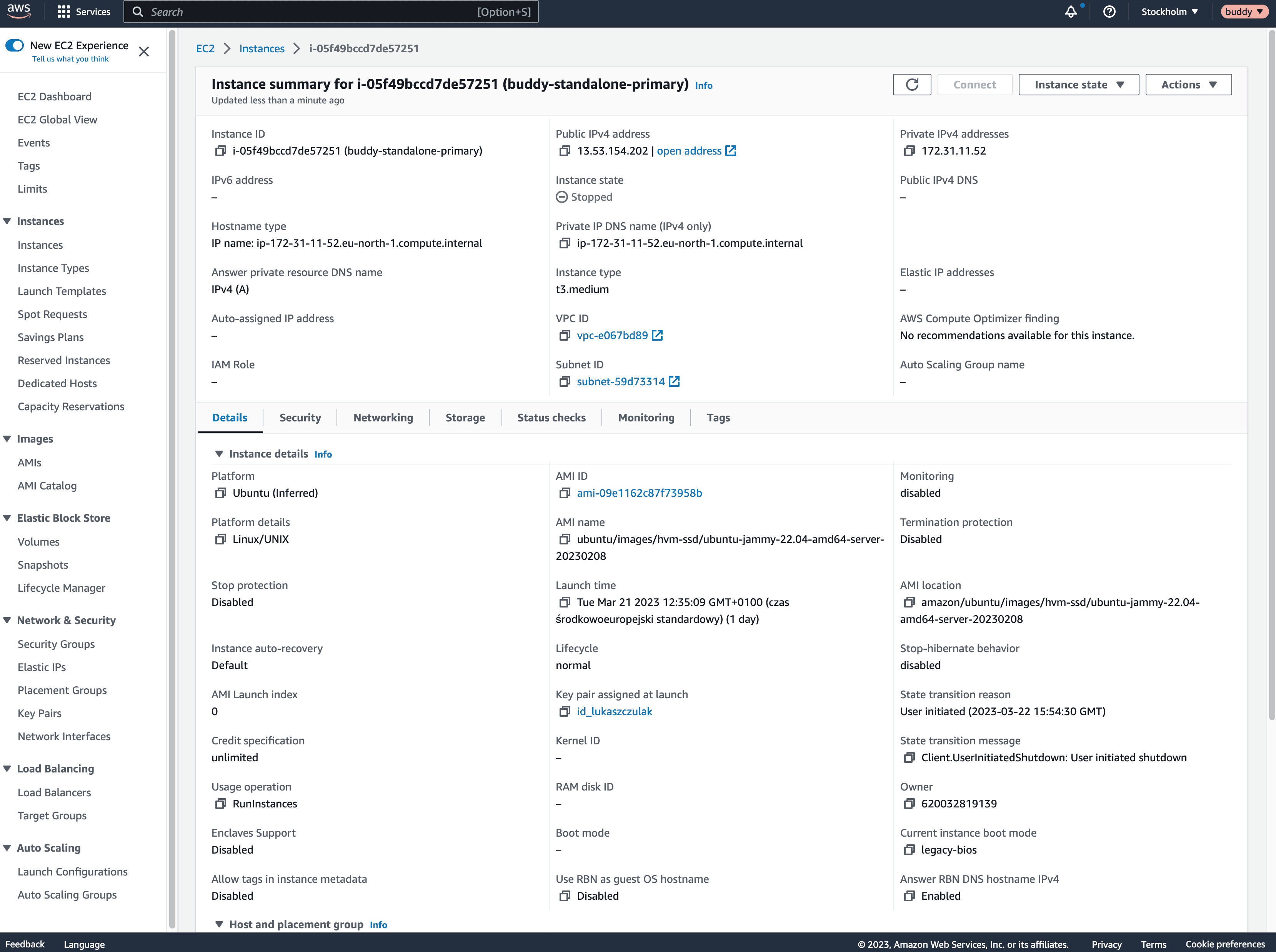
1. 安装Buddy于AWS
 |
|---|
- IPv4 公网地址 ($STANDALONE_HOST 必填)
- AMI ID ($INSTANCE_AMI_ID 必填)
- 区域 ($AWS_REGION 必填)
- 可用区域 ($AWS_AZ 必填)
- 示例类型 ($INSTANCE_TYPE 必填)
- 磁盘尺寸 ($INSTANCE_VOLUME_SIZE 必填,可保持默认值)
- 磁盘速度 ($INSTANCE_VOLUME_THROUGHPUT 必填,可保持默认值)
- 磁盘IOPS ($INSTANCE_VOLUME_IOPS 必填,可保持默认值)
- 工作器授权令牌 ($STANDALONE_TOKEN 必填)
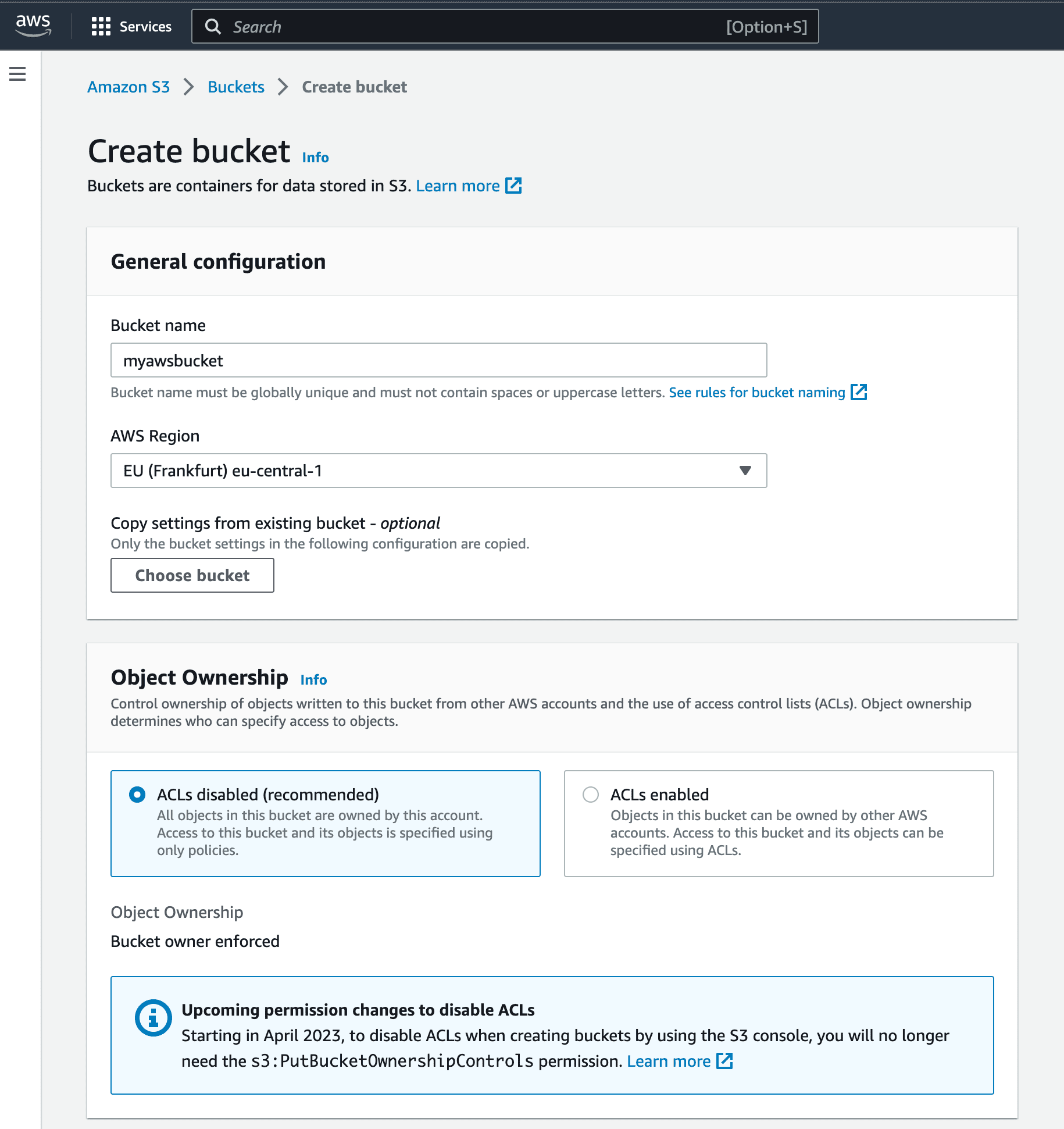
2. 为Terraform创建S3存储桶
在此,需要存储桶来存储Terraform配置。
 |
|---|
要求条件
- 必须与EC2实例上的Buddy位于同一区域
- 必须具有权限以便实例可以使用
- 存储桶名称 ($BACKEND_BUCKET 必填)
- TF文件名称 ($BACKEND_KEY 必填,可保持默认值)
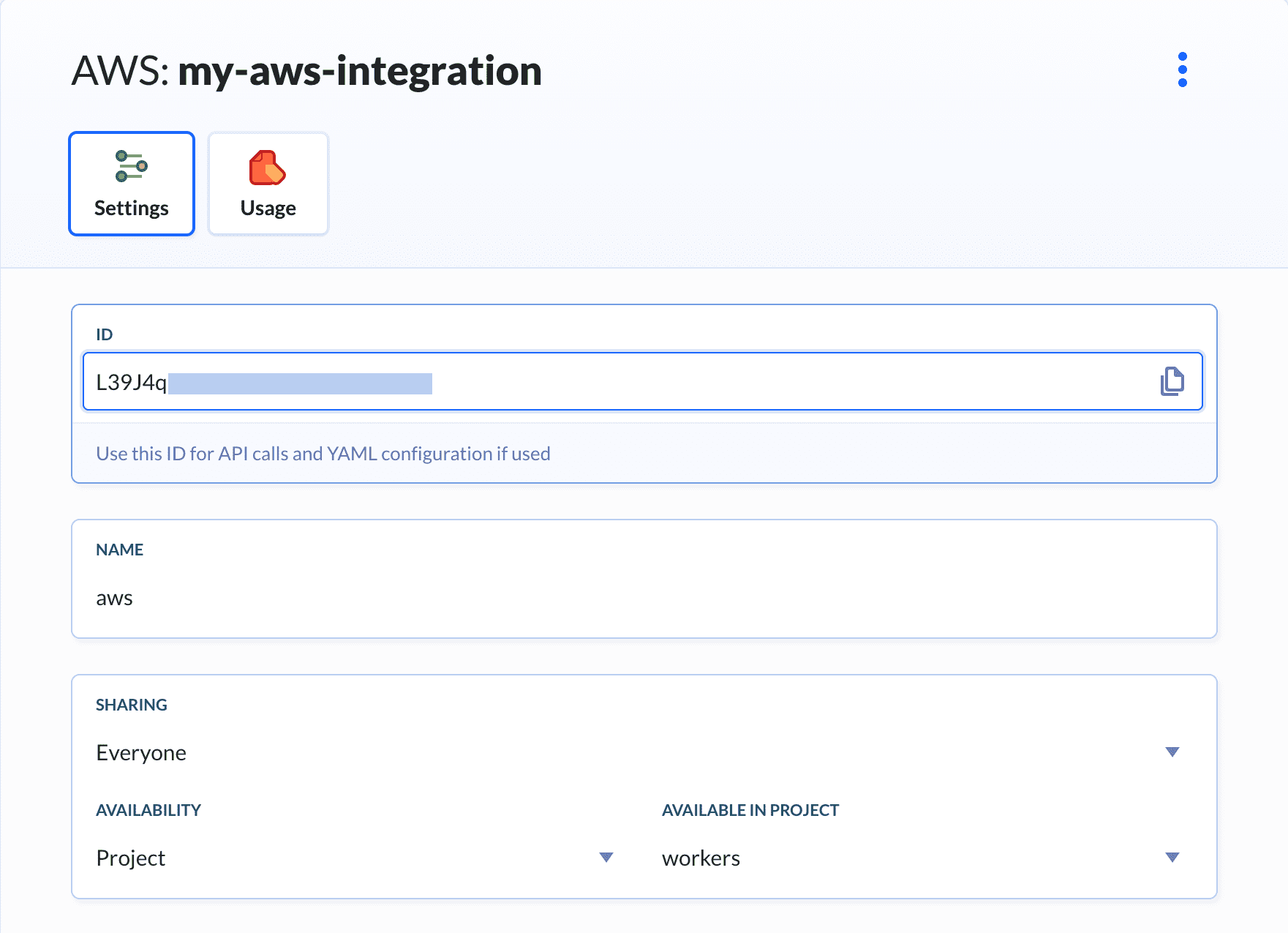
3. 添加AWS集成
现在我们需要将Buddy与AWS集成,以便它可以连接到AWS S3。
 |
|---|
- id_buddy_worker 内容 ($INSTANCE_PRIVATE_KEY 必填)
- id_buddy_worker.pub 内容 ($INSTANCE_PUBLIC_KEY 必填)
第四部分:填写Terraform变量
一切准备就绪后,您现在可以在/example_pipeline目录中的buddy.yml文件中填写变量,按照模板并确保格式正确:
variables:
- key: AWS_REGION
value: "eu-central-1"
- key: AWS_AZ
value: "eu-central-1c"
- key: INSTANCE_PRIVATE_KEY
value: "[PRIVATE KEY TO CONNECT TO WORKER]"
- key: INSTANCE_PUBLIC_KEY
value: "[PUBLIC KEY TO CONNECT TO WORKER]"
- key: INSTANCE_TYPE
value: "t3.medium"
- key: INSTANCE_AMI_ID
value: "ami-06ce824c157700cd2"
- key: INSTANCE_VOLUME_SIZE
value: "50"
- key: INSTANCE_VOLUME_THROUGHPUT
value: "125"
- key: INSTANCE_VOLUME_IOPS
value: "3000"
- key: STANDALONE_HOST
value: "172.31.15.212"
- key: STANDALONE_TOKEN
value: "[ON-PREMISES WORKER TOKEN]"
- key: BACKEND_BUCKET
value: "[BUCKET ON S3 TO SAVE TERRAFORM STATE]"
- key: BACKEND_KEY
value: "workers.tfstate"
从现在开始,每当您所需的马力不足时,流水线都会自动在您的基础设施中新建一个工作器:
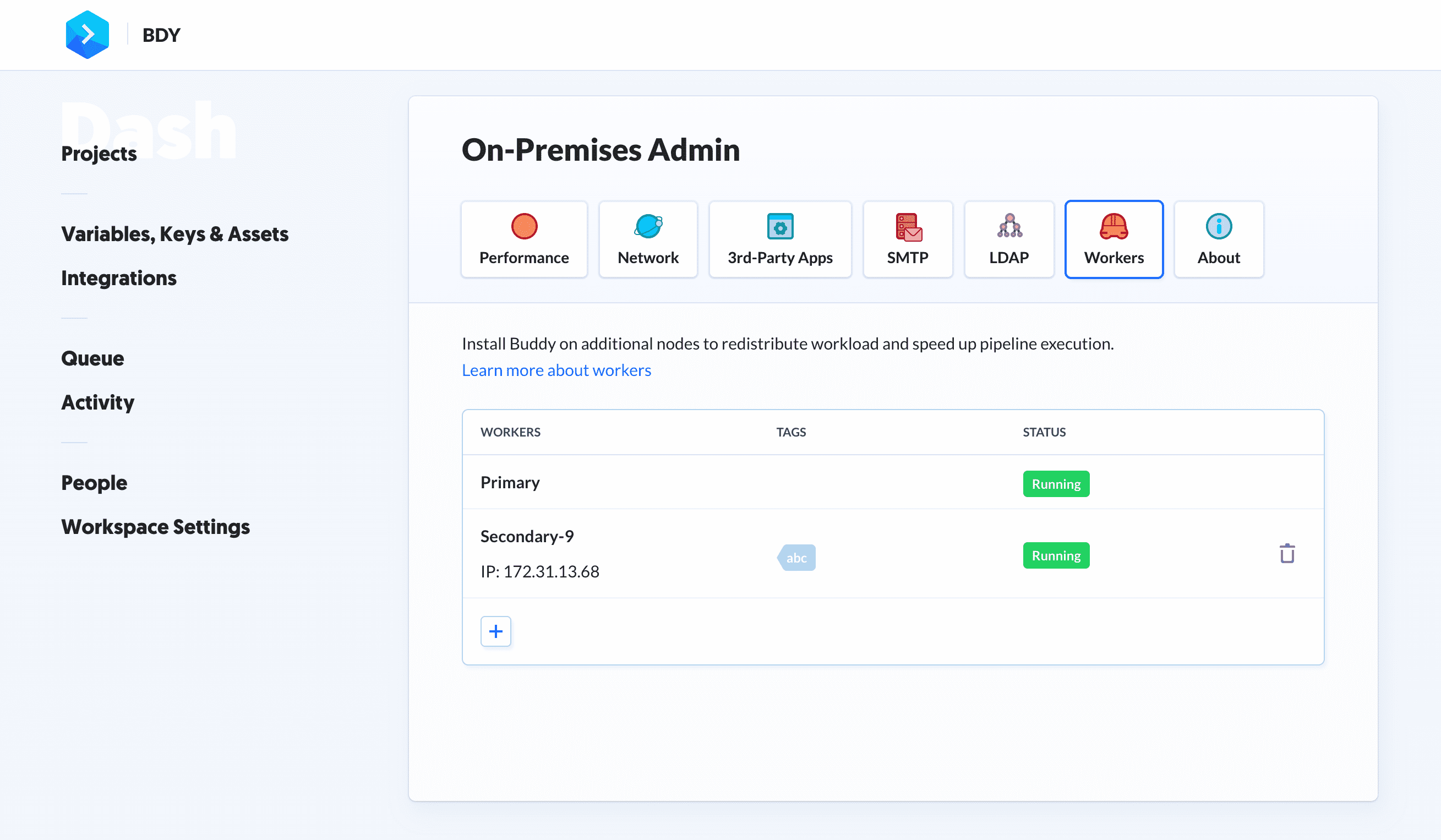 |
|---|
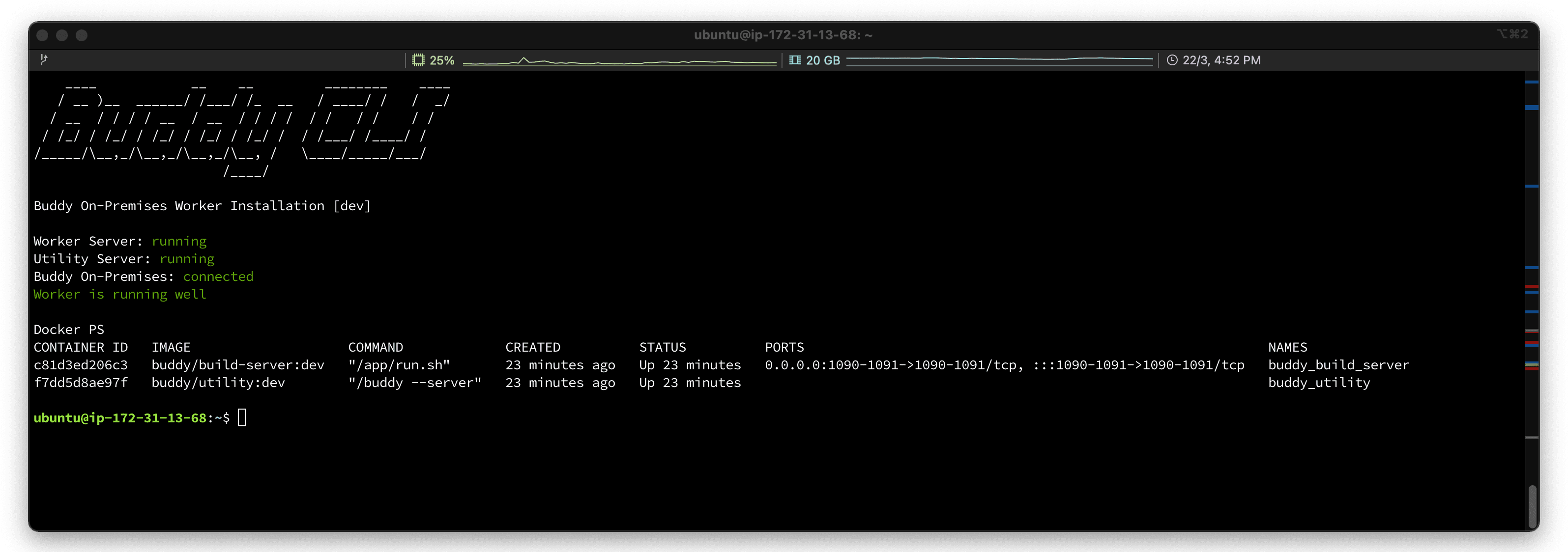 |
|---|